About Me
A bit about me
Hello, I'm Alexis Lowe, a principal engineer for a leading e-commerce business.
Formerly a cybersecurity expert, I now thrive in platform engineering. Outside of work, I indulge in my passions for travel, amateur photography, and gaming. Above all, I'm a devoted computer geek and enthusiast.
Join me on this blog as we explore the ever-evolving world of technology together.
FOSDEM 2020
FOSDEM is a Free and Open Source Software (FOSS) conference in Brussels. It is one of the biggest of its kind in Europe, with thousands of developers from all over the world gathering at the event. If you are into FOSS or you contribute to open source projects then this is the place to be. This year was an important year for FOSDEM as it was celebrating its 20th anniversary. To commemorate the occasion, a number of the talks were focused on the history and evolution of FOSS.
In this blog post I will walk you through the different talks I attended. Most of them were recorded and you can find them the full list of talks here.
The Linux Kernel: We have to finish this thing one day ;) solving big problems in small steps for more than two decades by Thorsten Leemhuis
This talk was a great overview of where the Linux kernel started and how far it has come, all the while taking small steps to solve the big problems. Thorsten also covers some of the changes that have impacted the kernel such as the creation of eBPF, which is allowing container technology to be more efficient and secure. The talk also briefly covers the state of filesystems in the kernel.
Kata containers on openSUSE by Ralf Haferkamp
Kata is an interesting take on containers. It allows you to swap the runc runtime with Kata. You can leverage small virtual machines for each of the containers you are deploying, giving even more isolation between them but still allowing you to take advantage of all the tools that are created for containers such as BPF, Kubernetes, podman and the OCI image format. It’s also available rootless.
Just before this talk I got to chat to Richard Brown, OpenSuse ex-Board Chairman, about podman and filesystems, all of this without realising who I was talking to. This is one of the things I love about FOSDEM - you can just bump into and casually talk to so many amazing devs.
How containers and Kubernetes re-defined the GNU/Linux operating system a greybeard’s worst nightmare by Daniel Riek
This was an interesting talk about the evolution of the computing stack covering the influence of the different technologies over time. It looked at how technologies like VMs, containers, binary packages and more, have drastically changed how we consume software and how we architect our solutions.
State of the Onion the road to mainstream adoption and improved censorship circumvention by Pili Guerra
This session was the annual report on the state of the Tor Project. For those of you that don’t know what the Tor Project is, it’s a distributed uncensored network which allows you to be anonymous while accessing the Internet.
This project is very important to me as I have seen its use to save lives and allow people to continue to fight their corrupt or dictatorial governments in a country where they are censored. The Tor Project organisation continues to improve the user experience of the Tor Browser, and they have built a very talented UX team who are utilising the latest in industry techniques. One of these techniques being user personas. User personas are used to help drive UX improvements across all the products the Tor Project distributes. They made the personas available freely, which got me and a friend discussing how it would be awesome to have a large repository of open source personas for all FOSS projects to take advantage of. This would help improve the user experience of FOSS products, reaching more people out there and maybe finally bringing the year of Linux on the desktop.
They also had some cool stats for people who like to dig into the numbers. For example, the current available network bandwidth is around 300Gbps and only half of it is being used. This is thanks to the community of volunteers that run well over 6000 relays.
Sadly, the report also showed a drop in the number of bridges. Bridges are relays that are not publicly published that allow people to access the network even when it is blocked or censored in their environment.
Lastly, they covered the release of the Tor Browser on Android. Previously, accessing the Tor network on mobile required 2 applications - Orbot and Orfox and the new release removes the complexity of having 2 applications to access Tor.
Homebrew: features and funding by Mike McQuaid
This was an interesting session on how Homebrew manages beta access by putting users who have ran the dev tools onto the beta channel. The talk covered how Homebrew uses feature flags to allow testing of broken/not yet ready features. Mike shared how Homebrew achieved better reach for funding by asking for it in a polite and non-intrusive way within the tool itself, where users would actually see it.
Reinventing home directories let’s bring the UNIX concept of home directories into the 21st century by Lennart Poettering
This is one of the talks that I missed out on but I will be waiting impatiently for the release of the recording. Systemd-homed will be a space to keep an eye on as it will fundamentally change how home directories are managed and setup on systemd Linux distributions.
An introduction to the Tor ecosystem for developers by Alexander Færøy
Another talk on the Tor Project, this time about how it is maintained and developed. It was a great introduction on where to start if you are interested in contributing to the project.
The path to Peer-to-Peer Matrix in which we throw away DNS and run Matrix clientside over libp2p and friends by Matthew Hodgson
As a die-hard fan of Matrix I was a bit sad to have to miss this talk, but the recording is available here. For those of you who haven’t heard of Matrix, it is an open standard for secure, decentralised, real-time communication. The easiest way to use it is via an app called Riot which I really like. This talk specifically detailed the instructions on how to make Matrix peer to peer, removing the need for servers and DNS.
Privacy by design by Trishul Goel
I would recommend this session to all web devs out there - it covered how to build a website that protects user's data by design, utilising available HTTP headers such as Content Security Policy and the new Feature Policy. All of this while creating a more performant website.
FOSSH - 2000 to 2020 and beyond! maddog continues to pontificate by Jon ‘疯狗’ Hall
This was the highlight of the conference for me. Delivered by Jon “Maddog” Hall, it was a great historical overview of the evolution of Freedom and Open Source Software, full of comedy and even got a bit emotional. I cannot recommend it enough especially if you love FOSS as much as I do.
Conclusion
FOSDEM was an excellent event and I would recommend it highly to anyone who is passionate about or would like to explore the world of FOSS. For me, it was also a great excuse to spend some time in Brussels - the city where I grew up.
A few pictures from the conference:
Using vim to keep track of the busy timetable of the event.
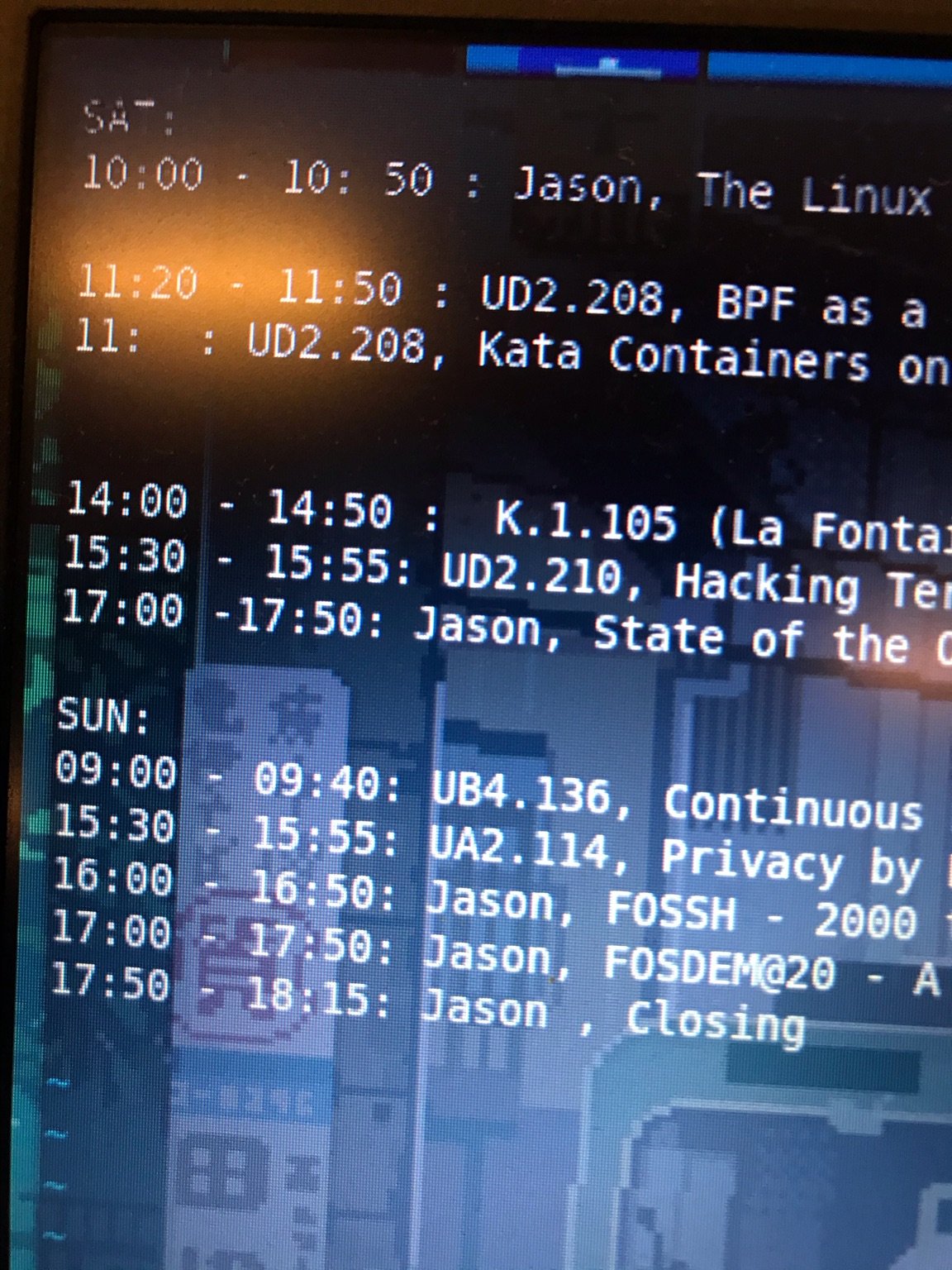
The hackers drink of choice and so full of caffeine.

openSUSE brought German beer to Belgium.

Some of my new favourite stickers in there.

So much great swag, my favourite being the Tor Project

Last updated 2025-06-02
AI and how I use it to help with my writing
Something about me that I don’t always share publicly is that I have Dyslexia. It specifically affects my ability to write long texts such as emails, documentation, feedback, blogs, cover letters, etc. Bizarrely writing code has never felt hard, so perhaps there is something else. Basically when I have to write a lot I find it incredibly hard to get what's in my mind into the form of text. It’s either full of mistakes (spelling or grammar related) or so involved that I loose interest and procrastinate.
Recently though I have discovered that I can leverage tools such as Notion’s AI or Chat GPT. What I end up doing is writing the outline of what I want to convey and then ask the AI to rewrite it. This has been amazing for helping me write large amounts of text. There is some downsides though and that is the output of these tools usually sounds grandiose or pompous, so I spend quite a bit of time prompting the AI to either shorten or simplify the words used. I found that the more context you give it such for example “I am writing an email for x from myself an x …” helps it generate text that is more appropriate.
One more thing I’ve found is that the AI needs very little to generate the text to the point that a few bullet points is enough to generate a page of feedback for example. I wrote down all the points I wanted to mention in the feedback and the AI generated a nice feedback email with the correct tone and embellishments.
Now asking the AI to write cover letters has also been eye-opening, the amount of information on a company that it is capable of picking up and introducing into the letter is crazy. To the point that even though I had done research on the company prior to writing the cover letter I was learning new things via the generated text.
To conclude, I was quite sceptical about Generative AI, but I am now convinced that this is game changing. We just need slightly better tooling. Perhaps Microsoft should bring back Clippy with a GPT-4 backend.
Last updated 2023-07-04
Comments
View Comments ReplyHashicorp Vault and docker-compose
Intro
Hello everyone,
This time I wanted to cover how I use Hashicorp's Vault to manage secrets used by docker-compose.
I've been using docker-compose to deploy the services I run on my home servers (I have 2 machines that host the services and Kubernetes was overkill) for a bit over 4 years now. The overall setup has served me well with it being simple and straight forward to deploy new services or update existing ones. All the compose files are stored in a git repo. The structure of the repo allows me to define "services" which are individual docker-compose.yml files that define a set of containers which together gives me a service I want to host at home.
I control variables that are shared between these services, but change based on the machine hosting it (Usually just the domain name change) via {{ hostname }}.env files. This has been working for me though one major downside is that the .env file can't be committed to git due to it containing secrets such as api keys.
This is where I've been leveraging vault and specifically vault agent to template the .env file, so I can push the .env template but not the secrets themselves.
Vault agent is capable of templating a file using go template syntax and generates the files with data from vault.
To do this we need a few things, first you need a running vault instance. I would recommend following the great docs from Hasicorp which you can find here.
Vault Setup
I have it setup as a service defined in docker-compose. A really simplistic example of the docker-compose.yml file:
version: "3.8"
services:
vault:
build: ./vault
command:
- server
cap_add:
- IPC_LOCK
ports:
- 8200:8200
volumes:
- /path/to/where/you/want/to/save/your/vault/data:/vault/data
restart: always
With ./vault containing the following:
Dockerfile:
FROM vault:latest
ADD config.hcl /vault/config/config.hcl
config.hcl:
storage "file" {
path = "/vault/data"
}
listener "tcp" {
address = "0.0.0.0:8200"
tls_disable = "true"
}
api_addr = "http://localhost:8200"
ui = true
Using Vault for storing secrets
So now we have vault running we can create secrets to do this we need the cli tool (You can do it via the WebUI, but I would recommend getting comfortable with the cli tool)
Creating a secret:
vault kv put kv/services/example apikey="super_secret_api_key"
# I would recommend prefixing the command with a space
# this will prevent it from saving it to your bash history
Once we have a secret created we can use it with the vault agent.
We first need to create a agent-config.hcl in which you will define the files you want to template:
auto_auth {
method {
type = "token_file"
config {
#Make sure to update this to the path of your home directory
token_filce_path = "/home/username/.vault-token"
}
}
}
vault {
#Update this with the address of your vault instance
address = "http://localhost:8200"
retry {
num_retries = 5
}
}
# Forces agent to close after generating the files
exit_after_auth = true
template {
source = "example.env.ctmpl"
destination = "example.env"
}
Next you need to define the template file example.env.ctmpl:
MY_NON_TEMPLATED_VAR=BLAH
{{ with secret "kv/services/example" }}
MY_SECRET_API_KEY={{ .Data.data.apikey }}
{{ end }}
This will fetch the services/example secret from the kv engine and write the value of the key apikey.
Generating us a file that looks like this:
MY_NON_TEMPLATED_VAR=BLAH
MY_SECRET_API_KEY=super_secret_api_key
docker-compose can now refer to that file making the secret available to the containers.
Conclusion
As you can see with Hashicorp vault its possible to generate .env files which can be used by your apps or in this case by docker-compose.
Last updated 2023-07-05
Comments
View Comments ReplyHashicorp Vault and direnv automating env secrets
In my last post I cover how I generated .env files using vault agent, and after a few weeks I discovered that you can leverage Hashicorp vault and direnv to automatically fetch secrets and make them available in your shell's env when you move to a directory containing a .envrc. With this I can set up git repos for colleagues where they can then run things like tests locally without them having to manually fetch secrets from vault or our organisation's password manager.
So to set it up you need to install direnv and have your Vault access setup. You can find the direnv instructions here and the vault instructions here
You can now create a secret on vault for example:
vault kv put -mount=secret test test-key=yourkey
# Don't forget you can put a space infront of this command and it won't save it to your bash history
# You can also read from stdin or use the web console
cat secret | vault kv put -mount=secret test test-key=-
Now you can create a .envrc file in your project directory and create a named variable that executes a vault get:
export MYSECRET=$(vault kv get -mount=secret -field=test-key test)
Now if you set up direnv and hooked it into your shell for bash : eval "$(direnv hook bash)"
When you move to that directory direnv will load that .envrc file into your shell's env.
N.B.: Make sure you have run direnv allow . on the directory otherwise direnv will not load the env files.
Last updated 2023-07-13
Comments
View Comments ReplyBTRFS Metadata and No space left errors
Before we start I wanted to give a bit of context about my data storage strategy. My data is in two categories: important and reproducible data (can be easily recreated or retrieved).
I follow these rules as best practice:
- Important data must have 3 copies:
- Local Network accessible copy
- Local copy on cold storage
- Off-site copy on cold storage
- Data integrity for important data is crucial
- Using
squashfsand then creating parity data of the archives usingpar2to mitigate bit-rot
- Using
- Full data integrity of reproducible data isn't important
- I can accept bit-rot but not losing access to the files
- Knowing a file is corrupt is important so that I can recreate or retrieve it.
- Local network data access must be fast and low latency
- Must not break the bank
Local data server setup
BTRFS was the best data storage format that fit the bill.
I created a storage pool consisting of two 4Tb Hard Drives and two 8Tb Hard Drives. The data is configured with the RAID0 profile and the metadata is configured with RAID1C4. This allows data to benefit from the bandwidth of all 4 drives and is able to fill all the space on the drives (no storage loss). The configuration also guarantees that the metadata will not get corrupted, making it reliable for detecting bit-rot in my data. In addition to this configuration I made sure that each disk has 100Gb of slack saved (this is a section of the disk that BTRFS will not use).
This setup has worked for me for over 6 years, and technically I started with just the 4Tb drives so BTRFS allowed me to grow my storage pool without any hiccups.
Recently I've run into a problem, all of a sudden my system put the storage pool into read-only mode and claimed it ran out of space.
Diagnosis
When checking dmesg, BTRFS kindly printed out exactly what had happened. The data section still had free space and so did system however metadata had run out of space!
To confirm this I ran sudo btrfs device usage /pool
which allows you to see the current disk usage per device in the pool:
$ btrfs device usage /pool
/dev/sdc, ID: 1
Device size: 3.64TiB
Device slack: 100.00GiB
Data,RAID0/4: 3.52TiB
Metadata,RAID1C4: 17.03GiB
System,RAID1C4: 32.00MiB
Unallocated: 1.02MiB
/dev/sda, ID: 2
Device size: 3.64TiB
Device slack: 100.00GiB
Data,RAID0/4: 3.52TiB
Metadata,RAID1C4: 17.03GiB
System,RAID1C4: 32.00MiB
Unallocated: 1.02MiB
/dev/sdb, ID: 3
Device size: 7.28TiB
Device slack: 100.00GiB
Data,RAID0/4: 3.52TiB
Data,RAID0/2: 195.00GiB
Metadata,RAID1C4: 17.03GiB
System,RAID1C4: 32.00MiB
Unallocated: 3.45TiB
/dev/sdf, ID: 4
Device size: 7.28TiB
Device slack: 100.00GiB
Data,RAID0/4: 3.52TiB
Data,RAID0/2: 195.00GiB
Metadata,RAID1C4: 17.03GiB
System,RAID1C4: 32.00MiB
Unallocated: 3.45TiB
As you can see, the disk sdc and sda are full with only 1.02MiB left unallocated. However, sdf and sdb still have plenty of space with 3.45TiB unallocated.
To help me better understand the state of the disks I drew a diagram.
The first thing that stood out was the behaviour of the RAID1C4 profile for the metadata. It forces BTRFS to create 4 copies of the metadata, one on each disk. So when I tried to write new data to the storage pool BTRFS failed and in order to protect the data and the storage pool, it had set the pool to read-only.
The fix
Fixing the issue was quite straight forward, but it required at least 1Gb of free space on each disk in the pool.
I used 10Gb from the slack section (the extra 100Gb of unused disk space) to resize the disks sdc and sda (device IDs 1 and 2) using the following commands:
sudo btrfs filesystem resize 1:+10G /pool and sudo btrfs filesystem resize 2:+10G /pool
Caution this requires the pool to be mounted in read-write, so you might have to umount the pool and remount it. See gotcha in the Conclusion.
This provides some extra space that BTRFS can use to move chunks around when it converts the metadata profile from RAID1C4 to RAID1.
RAID1 guarantees that the metadata is stored on 2 disks instead of 4, removing our deadlock.
The command to convert the metadata profile is the following:
sudo btrfs balance start -mconvert=raid1 /pool
This will kick off a balance operation.
Once it is finished running sudo btrfs device usage /pool shows what changed:
$ btrfs device usage /pool
/dev/sdc, ID: 1
Device size: 3.64TiB
Device slack: 90.00GiB
Data,RAID0/4: 3.52TiB
Unallocated: 27.06GiB
/dev/sda, ID: 2
Device size: 3.64TiB
Device slack: 90.00GiB
Data,RAID0/4: 3.52TiB
Unallocated: 27.06GiB
/dev/sdb, ID: 3
Device size: 7.28TiB
Device slack: 100.00GiB
Data,RAID0/4: 3.52TiB
Data,RAID0/2: 195.00GiB
Metadata,RAID1: 17.00GiB
System,RAID1: 32.00MiB
Unallocated: 3.45TiB
/dev/sdf, ID: 4
Device size: 7.28TiB
Device slack: 100.00GiB
Data,RAID0/4: 3.52TiB
Data,RAID0/2: 195.00GiB
Metadata,RAID1: 17.00GiB
System,RAID1: 32.00MiB
Unallocated: 3.45TiB
Again to better visualize, this diagram represents the state after the balance operation:
As you can see BTRFS removed the redundant copies of the metadata from the smaller disks and preserved it on the larger ones.
To clean up and reclaim the slack I ran the following commands:
sudo btrfs filesystem resize 1:-10G /pool and sudo btrfs filesystem resize 2:-10G /pool
Conclusion
BTRFS is incredibly powerful and super configurable, so configurable that like me, you can easily set up a foot gun. But it also has all the tools needed to diagnose and fix it.
The main thing that saved me was the slack space as without it, I would have not been able to run a balance. I recommend this as a best practice for anyone running BTRFS.
Another gotcha to be aware of if the pool has less than 1Gb of space, and you try to run a balance, the balance will fill the remaining space in the pool and cause it to switch to read-only mode.
It is impossible to cancel a balance once the pool gets into read-only mode. The only way to stop it is to reboot and make sure not to mount the pool on boot. Once booted, you can mount it with the skip_balance option (sudo mount -o skip_balance /dev/sdc /pool) which will set the balance operation to paused. Use sudo btrfs balance cancel /pool to cancel it and proceed with resizing the pool.
Last updated 2023-11-2
Comments
View Comments ReplyRust, learnings and journey
Rewriting My Skills: A Personal Journey Toward Better Engineering
In September 2021, I changed my career, I went from the world of Cybersecurity to Software Engineering and System Design. Not long after, I was promoted to a Principal Engineer role which I felt ready for due to my extensive background in designing, building and deploying complex, resilient systems and my ability to take the lead in these types of projects.
I quickly learned that my software skills were really quite superficial. I had spent most of my career up to that point learning to find vulnerabilities in other people's code and the ins and outs of memory buffers, but I never had to write quality code myself.
In my new role, this started to bother me quite a bit, I couldn't always explain why the code was not right even though my instinct said there was something wrong, and for the first time in a long time, senior engineers on my teams would confuse me. It was a new challenge, and I was really up for it.
The start
In order to reduce the gap in my knowledge, I incorporated coding into my life as a hobby. I first started looking into the languages the company I work for uses, C# and TypeScript, however at the time I was reading a lot about Rust and also listening to On The Metal podcast which lead me to decide to learn Rust instead. My reasons behind the change were that I was doing this for myself and not the company (though the end result has been beneficial in that respect as well), and I had also read a blog post claiming that Rust holds your hand and helps you avoid simple mistakes. This, as it turns out, was both accurate and misleading.
I had written code in Rust before but in order to learn more I started by implementing Huffman Encoding in Rust.
Huff-Tree-Tap v0.0.x
In my first attempt to implement Huffman Encoding, I made quite a few mistakes and 100% misunderstood the borrow checker.
The mistakes
My first major mistake was that I didn't embrace the Result and Option types and ended up with a load of unwrap()s. Rust's error handling system is something that I have now learned to love but back then it was confusing and frustrating to call a function and not get the value.
My second mistake was that I fought with the borrow checker rather than let it tell me what was going on. So I ended up with a lot of unnecessary clone()s and a lot of mut references when they weren't required by my functions. I made the mistake of having some functions that did far too much because I had gotten tired of the moved-out-of-scope errors.
The good
Rust's testing framework simplicity meant that I wrote a lot of tests (at the time I was also learning about test driven development for work).
Rust's documentation also helped a lot. The second I learned that I could generate docs.rs from my own code and have it include the docs for my dependencies my inner documentation nerd took the wheel and went off to the races.
Another thing I did was make sure I knew how to package my library, which lead me to learn how crates.io and cargo work but also how build a CI/CD pipeline for Rust. These ended up being very straight forward.
In conclusion, I managed to create a working Huffman Encoding library which was working and well tested. If you are curious you can find the last v0.0.x of the code here
Learning More
After implementing Huffman encoding, I felt like I was ready to take on something new. This time around I needed a project that was actively used and had more eyes on it as I wanted feedback on what I was working on.
One of the technologies that fascinates me the most is OpenPGP, especially the identity side of things (the subject of my final year project in university was on Enforcement of Access Control in P2P Networks Utilising OpenPGP). The coolest project in this space in my opinion is Keyoxide. At the time I was looking for a public project to work on the core maintainer of Keyoxide's was rewriting core functionality in Rust.
I took the opportunity to brush the dust of my bound copy of RFC 4880 and read the documentation on Sequoia (an implementation of OpenPGP in Rust), going on to help implement the Keyoxide core in Rust.
Here I learned a lot more about the methods of writing code specific to Rust, things like map, iter, match and more importantly Rust's error handling. I also started using cargo watch -x fmt -x check -x clippy -x test to make sure what I was writing was following linting rules. Working on this also gave me the opportunity to work with other engineers in Open Source codebases - something I had once only dreamed of.
At this point, I was more confident with software engineering, and I was able to bring more to discussions about coding at work.
Huff-Tree-Tap v0.1.x - 3 years later
After 3 years of constantly looking for ways to improve my software engineering skills, I decided to revisit my original Rust project. This time around, I was looking to refactor the code to follow the new practices I had learned, but I also changed my mindset from looking at it as a hobby project to treating it as if it was critical software.
Linting and adding benchmarking
My first set of refactors involved using clippy and implementing a new benchmark test using thecriterion framework. Benchmarking helped me measure my progress and track if the refactoring I was doing actually improved performance.
The benchmark I was running was encoding and decoding an array of 64 000 bytes and at the beginning, the results were as follows:
Huffman/huffman_encode time: [1.0851 ms 1.1029 ms 1.1223 ms]
Huffman/huffman_decode time: [1.1085 ms 1.1384 ms 1.1726 ms]
Most of the linting involved cleaning up the unnecessary clone() and mut from the code but also removing the unwrap() calls and implementing better error handling.
Clean code and breaking down functions
Next I focused on breaking out each part of the system and creating structs that represented the different data structures I was using. I implemented traits to provide functions on those data structures. This helped split up the different parts of logic, allowed me to reduce how much each of my functions was doing and gave me a clear and concise view. As I was treating every change as if it was applied on critical software, I had to make sure every one of my commits contained tests, including checking the external APIs hadn't changed, and had successfully passed those tests. Rust's type system and testing framework really shined here and made doing these refactors a breeze.
Once I broke everything out into its independent moving parts I restructured the repo, so each part had its own file rather than being a very long lib.rs.
Benchmarking post the refactor
Benchmarking the refactor was as easy as running cargo bench again and the results were:
Huffman/huffman_encode time: [627.06 µs 643.82 µs 662.17 µs]
change: [-45.908% -43.891% -42.096%] (p = 0.00 < 0.05)
Huffman/huffman_decode time: [1.1085 ms 1.1384 ms 1.1726 ms]
change: [-30.631% -28.453% -26.042%] (p = 0.00 < 0.05)
As this shows, I managed to achieve a pretty major improvement without changing the behaviour too much, just moving code around and using the borrow checker correctly. If you want to check it out click here
Huff-Tree-Tap v0.2.x - Chasing the optimisations
At this point I was happy with how the code looked, but I really wanted to continue improving the performance.
To find the slowest parts of my code, I used cargo flamegraph to profile my repo. It uses Linux's perf under the hood to generate these detailed flame-graphs that help visualise the runtime of functions.

This led me to realise that manipulating strings is very slow. When I originally wrote this library, I used String to store the bit format encoding as I had found that you could format a u8 into its binary representation by just calling format!("{:b}", x).
To optimise this I created a type to represent bits called Bit which was u8s consisting of 0s and 1s. To store a u8as a set of Bits, I created a Vec<Bit>. I then wrote traits for the conversion of u8 to a Bit, Vec<u8> to Vec<Bit> and vice-versa. With u8 being the smallest byte addressable unit in Rust, this meant my functions were using less memory but also were making no calls to any of the functions from String.
The flame-graphs continued to be super useful in identifying the longest function calls and the hot paths to focus on to improve the performance.
The benchmark results after these improvements looked like this:
Huffman/huffman_encode time: [406.26 µs 414.72 µs 423.78 µs]
change: [-39.115% -37.313% -35.510%] (p = 0.00 < 0.05)
Huffman/huffman_decode time: [392.79 µs 397.60 µs 404.15 µs]
change: [-62.323% -61.680% -61.009%] (p = 0.00 < 0.05)
From the start of this project, I had managed to improve the performance of both encode and decode by 125%.
Learnings
In the end, what really mattered was that I became comfortable getting my hands dirty and digging deeper into the craft of writing good software. I went from knowing how to spot issues in code to actually understanding why they happen and how to fix them. Along the way, I learned to trust the language's constraints, embrace benchmarks to guide meaningful improvements and the importance of testing and documentation. This isn't just about coding better - it's about seeing problems clearly, breaking them down, and treating even a personal side project with the care and attention I'd give to a production-level system.
Ultimately, the skills, confidence, and mindset I built during this journey have made me a stronger Principal Engineer. Now, when I look at a piece of code, I'm not just relying on my instincts, I can actually explain why something should be done a certain way to others.
And the journey doesn't end here; I'm still learning, still experimenting, and still finding new ways to become a better engineer every day.